Tools Infrastructure for Production
Working in a team on a project that will span several months or years, you will need to create an infrastructure to support your team as the codebase grows. In this article I will discuss a bunch of tools, what they do and why you would need them. Every project, team and business is different though, so this is part of my experience and you will need to tweak the selection of tools and their priorities to your own use-case.
If you write production code in a team these are the things that you need to think about:
- IDE (Integrated Development Environment)
- Code repository and Hosting
- Repository Client
- Feature and bug tracker
- Test Framework & Coverage
- Code Linter & Formatting
- Code Review System
- Documentation System
- CI (Continuous Integration)
- CD (Continuous Deployment)
- Environment Management
Let’s have a look at all of them with some examples, but also consider how this ties into a process and what value you are hoping to get. Remember that using a tool just to tick a box is only increasing your overhead of tools to maintain. You should only invest in a tool if you tie it into your development process and make sure you actually benefit from it. Otherwise, don’t bother. So for example if you are simply wanting to explore some tech or code to learn, then you don’t need many of the tools listed. Or if a project is flagged as Prototype or Research, then again you can ignore some of the elements. if you are in the startup phase of a business then it is not so clear cut if you can actually afford to cut corners - you can consciously decide to ignore some but you will build up technical debt which you have to pay back later.
IDE
What for: Your coding and debugging environment.
Why: Powerful tools for happy = productive devs
As a developer this will be the tool you spend most of your time in, so it is important to get it right. Happy developers are productive developers and just as you shouldn’t sit on a crappy chair, you need to get your code editor right. There is no single best IDE, many specialise in specific domains, so you would make a very different choice for writing a game to a web app to a data science project. What is common though is that you need to make sure it has a rich eco system and supports many of the code related tools further down the list. You want to be able to run tests, see linting and coverage information. It also needs to provide you with the right debugging environment to track down and eliminate bugs. There are some great free editors out there like VS Code, but I would always make the case that if you need a particular functionality that makes the life of a dev easier, then it is worth going for a commercial product. You will get dedicated support and whatever it costs will be a fraction of the time a developer wastes with substandard tools.
What can you expect from a good IDE? A really good text editor, Code completion, syntax highlighting, linting, formatting, run and debug with a single click, file and folder management, project management, repository integration (although you may prefer a dedicated client), compiler and interpreter management.
I have used Visual Studio for a long time developing a graphics heavy C++/C# application and it worked very well over the years. Funnily when it comes to writing python code I never even tried it on Visual Studio and went straight to VS Code which has a rich eco system of plugins and although at times a bit slow, is a great feature rich tool.
Do you want to standardise your IDE across the team? I would argue that you should. If you have different tools then you will need to support the different environments, shared coding or debug sessions will be hampered and on-boarding new devs will be problematic. Learning a new IDE as you join a company goes faster than you think and working the same way builds cohesion.
Examples: Visual Studio, VS Code, NetBeans, Atom, PyCharm

Code repository and Hosting
What for: Store and share code, Branching and merging policy, Pull Requests
Why: Build stable code, isolate messy dev work from production. Your product undo button!
It may seem obvious as code has been living in repositories for a long time now, but no team can work without one. Code is the output of a developer and the basis of your product. It needs to live somewhere and that is a repository, which is hosted either locally on your premises or in the cloud. In traditional software teams this is very well accepted, but I would also argue that with the newer breed of data related jobs (Data Engineer, Data Scientist, Data Analyst), this is not always the case. SQL is just another programming language and you should store it centrally accessible to other developers. Repositories give you a history of all the changes anybody in the team has made, so you can roll back to a known good point at any time. You can create copies of any state of the codebase and branch or fork off to try something new or add a feature without impacting the main product. Once done and tested you merge you changes back to the main product code base.
Git has become the defacto standard for repositories now, but it is worth remembering svn/subversion and perforce amongst others that may have benefits for certain situations. Also consider a dedicated data repository like DVC for Data Science/Machine Learning projects as git isn’t the best tech to store data.
Next to the repo technology you can also chose from a bunch of hosting services (or run a server on your own premises). They will actually store your code and provide additional features such as Pull Requests.
Examples repository: Git, Subversion, Perforce
Example hosting: GitHub, GitLab, Bitbucket, Azure DevOps
Repository Client
What for: Simplify your work with the repository.
Why: Reduce the complexity of repositories and make less mistakes.
So clearly once you have a repository and got it hosted somewhere you need to decide which client to use to interact with it. With Git being the most popular type of repo there is a good bunch of clients you can choose from. Plus many IDEs come with a Git client built in. It may not be strictly necessary to streamline a team on the same repo client, but this can create conflicts as different clients represent the commit history in different ways, so this may lead to different style of committing code. With git you obviously get the command line experts as well as highly visual clients like Git Kraken. Both do the job, but have a very different view of the same thing.
In my experience one of the biggest source of problems is not which client a team or individual uses. It comes from the fact that git, although used everywhere, is not easy to use. It is a complicated, very powerful system and whilst many tools make it look very easy, once you try to merge a hundred files and try to handle merge conflicts, things will break. And yeah, you can break your repo and potentially lose code if you do the wrong thing. Working with the repo is an important part of working productively in a team, yet it isn’t everyone’s favourite task. Once you’ve finally got that new feature working you are eager to get it in the main branch quickly. Therein lies the challenge merging quickly is never a good idea and you’d want to take it slowly and double and triple check nothing breaks. Obviously Tests help too.
Remember this is still in the README.md of the Git repository:
The name "git" was given by Linus Torvalds when he wrote the very first version.
He described the tool as "the stupid content tracker" and the name as (depending on your mood):
- random three-letter combination that is pronounceable, and not actually used by
any common UNIX command. The fact that it is a mispronunciation of "get" may or may not be relevant.
- stupid. contemptible and despicable. simple. Take your pick from the dictionary of slang.
- "global information tracker": you're in a good mood, and it actually works for you.
Angels sing, and a light suddenly fills the room.
- "goddamn idiotic truckload of sh*t": when it breaks
Example clients: Command line, Git Kraken, Souretree
Feature and bug tracker
What for: Plan your work, track features and bugs
Why: Have clear and transparent team priorities.
There is an abundance of different tools that will promise to make your life incredibly efficient, so much in fact that the work will do itself. Not quite… You clearly need one, but what is more important than chosing one over the other, is how your team uses it. Clearly its purpose is to make sure that the development team has a written record of all the items that need to be worked on. So it is the output of the product team together with the development team organising the work in such a way that it is well understood and clear. You can use the best feature tracker in the world and still make an absolute mess.
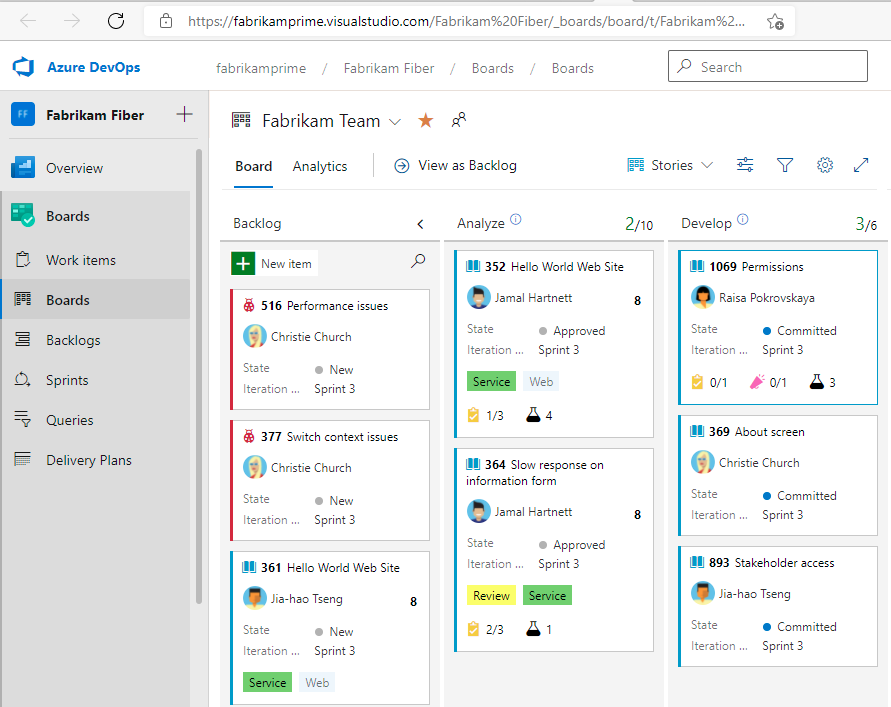
I have used Azure Devops Boards in the past and it did a decent job. Setup and management is a bit Microsoft centric, i.e. not always obvious, but it is very flexible. Key thing is you can group work by milestones, product can create feature backlogs, you have a way to prioritise things and it supports the notion of sprints or iterations, so it is clear what should be worked on in a given time frame. Work items go through a life-cycle, so they are created, then added to the current work, picked up by a dev, completed, reviewed, tested, merged and finally documented. So all along the way it is clear, who owns this particular task and what state it is in.
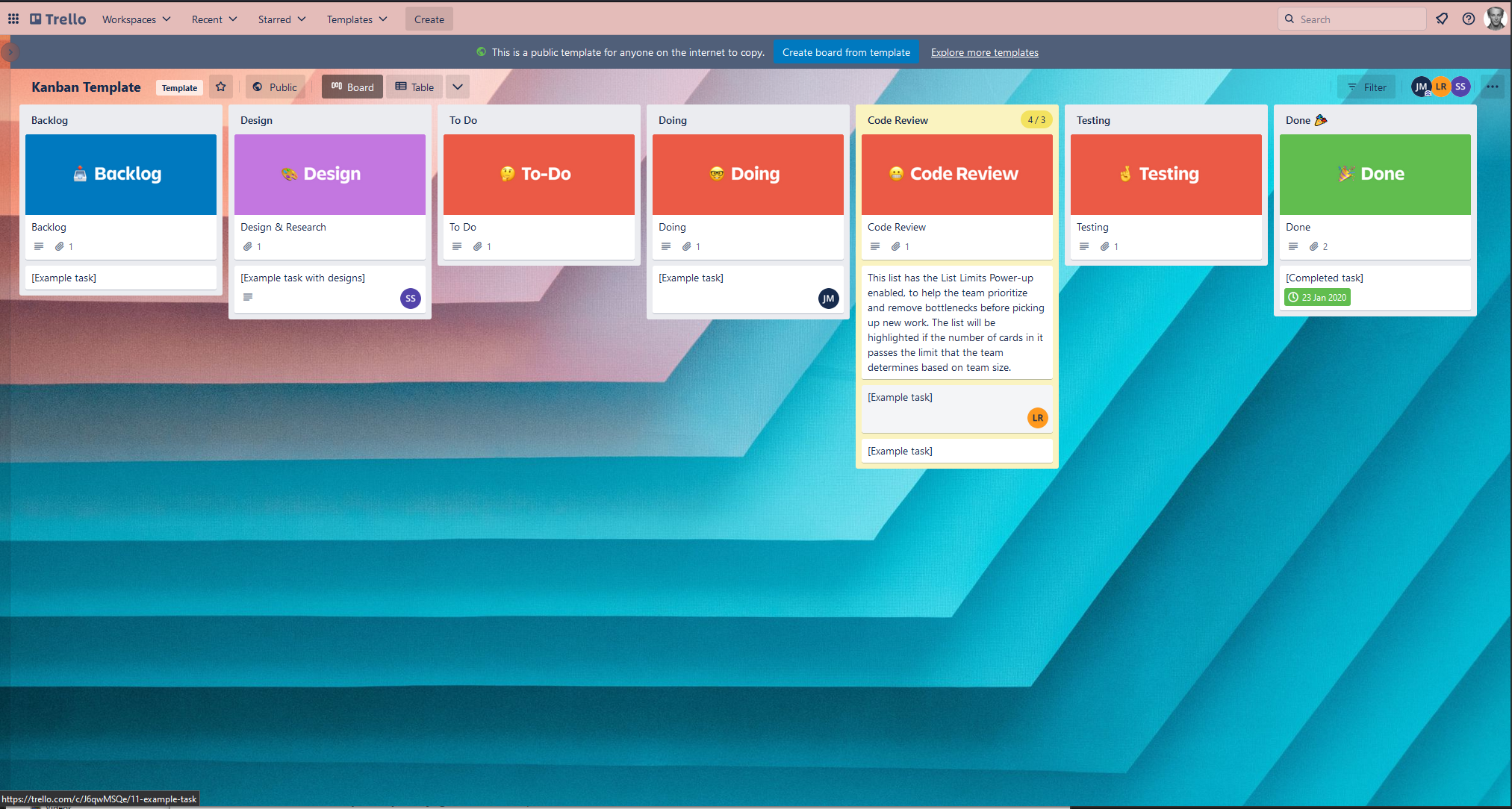
A lighter way of doing this is to use Trello. Just get a Kanban board going and everybody can use it in no time. It is very obvious how work items travel through the whole development cycle from “Backlog” to “Done”.
Test Framework / Coverage
What for: Create Unit, Integration and End-to-end test, identify code not covered with tests
Why: Ensure product remains stable, encourage good design by loose coupling components, code for others
Any serious dev team will have a test framework and strive to create as many tests as possible to make sure the product is stable and does what it is meant to do. Why? Because it is the only way to know for sure that after that last merge it still works. Well, apart from doing a bunch of manual tests, but that is boring and cumbersome and you really want to automate whatever you can. I have had many a debate whether writing test speed you up or slow you down. I just know that whenever I write a test (unit, integral or end-to-end) 9 times out of 10 I fix at least one bug along the way, which would have made it through to production and then turned into one of those problems further down the line. Remember that a bug fixed during development has a fraction of the impact (read cost here) than one that made it through to a customer. So, testing is very important. Because it is, we should make it as easy as possible to write automated tests. That is what a test framework is for, so all the boring boilerplate code for discovering and running tests is just done. Ideally it integrates into you IDE and while writing that spanking new feature you can tap away at that test at the same time.
A quick word on test classification into unit tests, integration tests and end-2-end tests. One of the best definitions I found was that unit tests work on classes and functions directly, nothing outside is of concern. Integration tests try to use multiple classes together, ensuring they are and remain compatible with each other. And end-to-end tests run a whole workflow from start to finish and only really push some input in and check for the outcome. Obviously if you product is GUI heavy then you may also use a GUI test framework to validate whatever the user will throw at you. Testing is a big topic and should be tackled right at the beginning of a product lifecycle. Retrofitting rarely works both technically as well as process wise. Once a team gets going without taking on the responsibility for testing, it is very hard to come back.
Code Coverage is the little brother of your Test Framework. It helps you understand which parts of the code are not touched by any tests yet. It is not the ultimate truth though, as you can create a test that covers all code, but still have bugs in it. But it is rather fun and very satisfying working towards 100% code coverage. So I would see it as much as a motivational tool as much as one giving useful stats back.
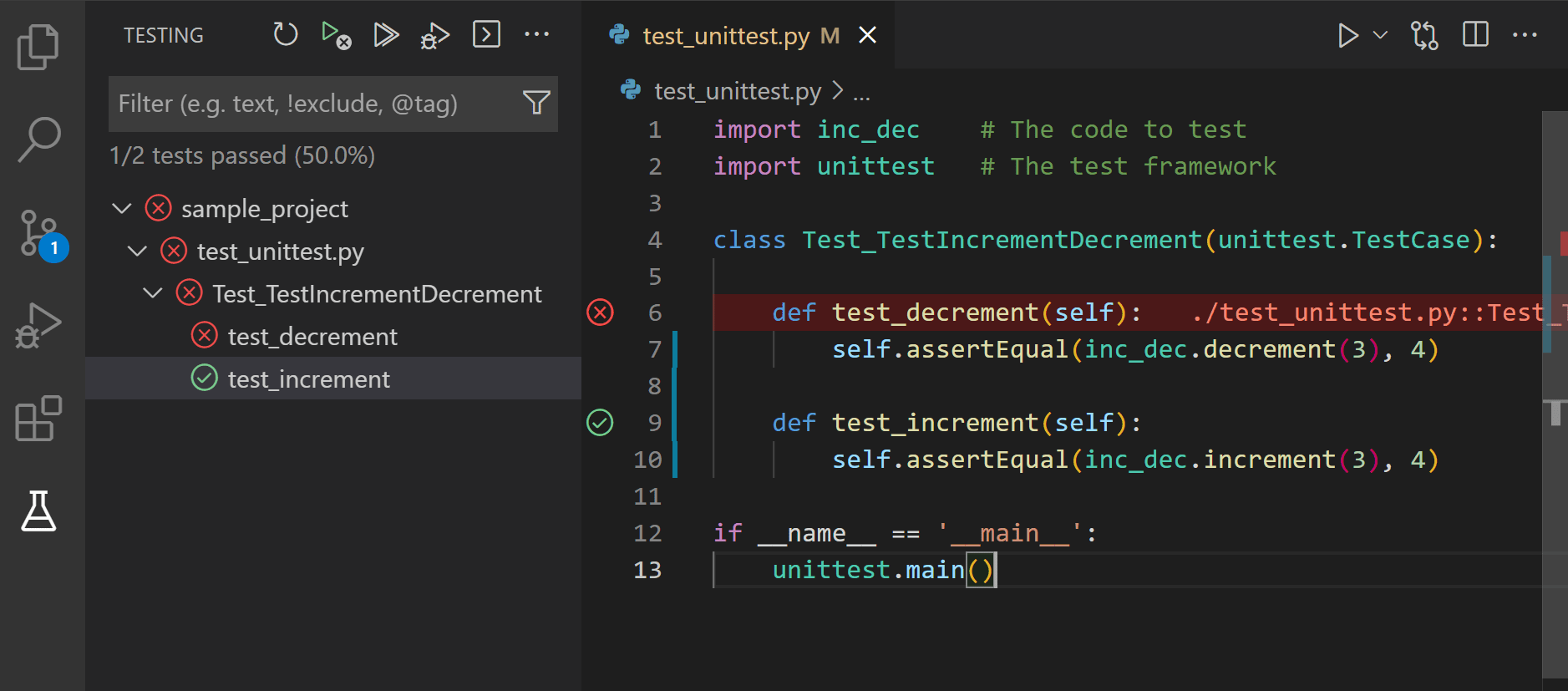 source: code.visualstudio.com - VS code example
source: code.visualstudio.com - VS code example
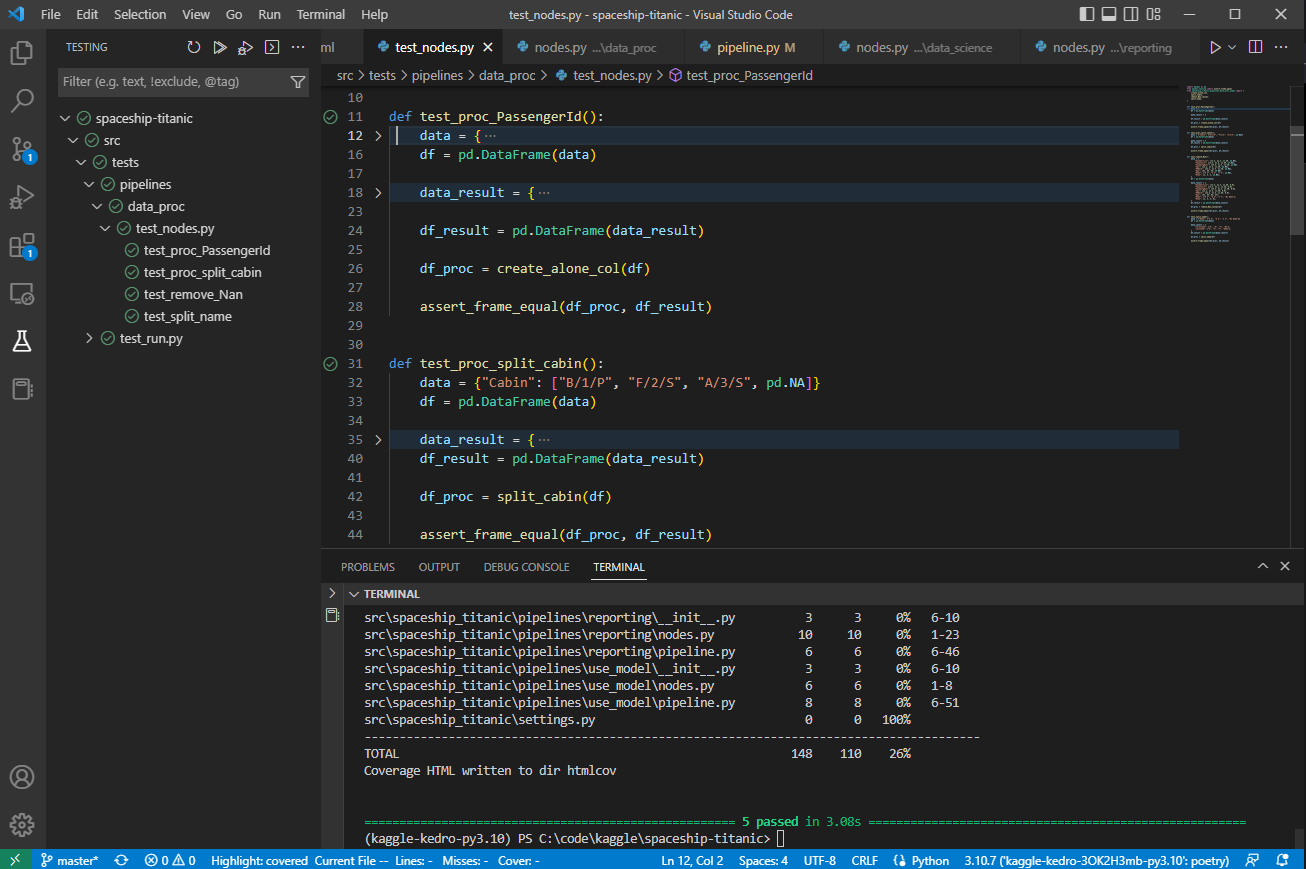 pytest integrated into VS Code IDE.
pytest integrated into VS Code IDE.
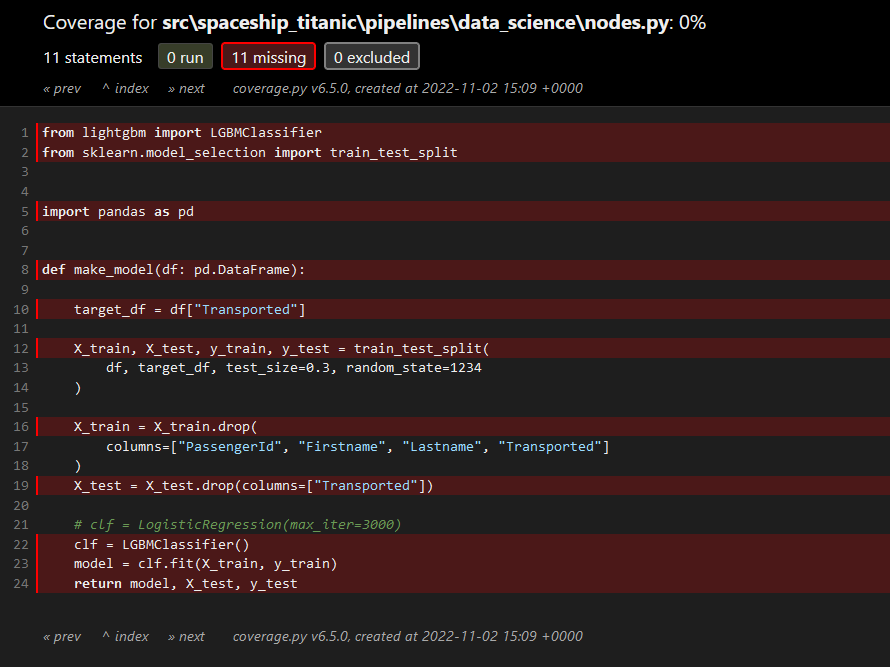 Html coverage report with a lot of code not covered by tests.
Html coverage report with a lot of code not covered by tests.
Code Linter & Formatting
What for: Static code analysis tool to highlight problems and format code to be consistent across the team.
Why: Write code for others (including your own selfin the future). Avoid bad practice and bugs.
When you start out as a developer you think that your will spend most of your time writing code. Little do we know that we actually read code a lot more than write it. You write it once, and already when you start refactoring it you will have read over it several times. Add code reviews and then writing tests and fix the odd bug. I couldn’t find any research or evidence to back it up but I would agree with Robert C. Martin’s quote: “Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code."
Regardless of this argument you should be proud of your craft and make sure to churn out beautiful elegant, readable code. Until we have AI helpers turning bad code into good code, we can employ the help of linters and formatting tools. It doesn’t help with bad design, but at least makes things easier to read as it takes care of not having too many characters per line, the correct indentation - that sort of stuff. Life’s too short, get a tool to automate this! And please no discussion around tabs vs spaces. Just decide and then automate.
Examples: Python: Pylint, flake8, Pylama, Black, isort, autopep8; C#: ReSharper, EditorConfig
Code Review System
What for: Get code reviewed before merging to main branch
Why: Improve code quality, share knowledge, team communication
The Code Review System is part of your repository eco system and provides you with a managed process to share your changes with one or more developers so they can review and comment on what you have done. This happens before your changes are merged to the main branch. If you are using Azure Devops, GitHub or Bitbucket then those are called Pull Requests. GitLab calls them Merge Requests. it doesn’t really matter which one to use, key is to get eyes on your changes by a different team member to give you feedback what you have done. It is also a great way to spread knowledge of one part of a code base to different team members or mentor junior developers.
The tools all work in a similar collaborative way, key is that developers interact and work together to improve code quality. Code style and formatting should only be covered here if not done by an automated tool. Discuss and share architectural decisions, code patterns used, test coverage - that kind of stuff. If you are in the same office, why not do a code review on the same machine over a cup of coffee and some cake? More fun and social.
Examples: Azure Devops PR, GitHub PR, GitLab MR

Pull requests integrated into VS code: source :marketplace.visualstodio.com
Documentation System
What for: Create code that documents itself, plus a framework for additional documents
Why: Make it easy to understand how everything works together, quick onboarding, design better code
The nature of writing software is that you come up with new ideas. It is not called designing software for nothing. So where do you put your thoughts and insights? Into code of course, but it is a bit unfair for anybody who comes after you to read all the code to figure our what you were trying to build in the first place. So how to document those architectural decisions for future developers? You will need a place where to put them, and just a cloud drive doesn’t cut it - it needs to be in your repository! Markdown is a nice simple format that is repo compatible (your can track and see changes) and you can simply place those docs throughout your code folder structure. Look at the README.md that is used throughout GitHub in the root of any repository, there is nothing stopping you from writing some more readme’s throughout your code base and anyone browsing it will instantly get your ideas.
The other interesting side effect of trying to document your grand design is that you will probably improve it while writing it down. Or at least you will develop a severe allergic reaction trying to document a bad architectural design, so you can have another go and improve it. Writing a clear document about a bad software design is surprisingly difficult - you should try it.
Further you can use a tools like Sphinx, MkDocs or DoxyGen to analyse your code and extract classes, functions and members together with comments annotating them and create a webpage as reference. It is very effective when creating code that has a wider audience, check out the Python documentation which is autogenerated with Sphinx. For an internal project you could argue that it is faster to use your IDE to lookup function signatures etc, so might not be as useful. Regardless you should define very early on what commenting style you will adapt as a team. If you make it Sphinx/DoxyGen compatible then you get a Code Reference for free (ok, nothing is ever free, but near enough).
Plus those tools can collect all your README.md and other .md files and bind them together into a webpage, so it then serve as a combined architectural and code reference handbook. All part of your codebase and version tracked in your repository. Neat!
Examples: Sphinx, MkDocs, DoxyGen
MkDocs documentation created with MkDocs - source: https://www.mkdocs.org/
CI (Continuous Integration)
What for: Automatically build and test code changes
Why: To have software that builds and runs
The “why” sounds a bit obvious, but it totally isn’t. Code isn’t useful unless it builds in to a product and works. So a dev proclaiming that he/she just finished the next big feature and when you ask for a demo it doesn’t build nor run. So how do you ensure that something works? You have a CI system that will a) build your code and b) run all tests.
Building is pretty straight forward and it either builds or someone has forgotten to commit that one file, or changed some dependency, or switched a flag that causes something completely independent to just not build. It is truly astounding what little things can cause a build to break and breaking it will, so CI has to build your codebase, ideally every time someone commits code. With a very large codebase this might take considerable resources, so it may not be practical. But in that case you may want to change your architecture so that you have smaller projects that can build independently. But I digress, you get the point that code needs to build on a machine that isn’t the developers in order to verify that indeed it does build.
Running and passing the tests is the second requirement and the usefulness of this step really depends on how good your test coverage is. If you have very few test, then it may not tell you much, but let’s imagine just having one test - it will start the application, check it is indeed running and then stop it. This one test would have already been beneficial for our developer earlier.
It sounds somewhat cruel and often can be perceived as this getting in the way of happy developers. But in reality it is just something that good teams embrace, they are keen to create working products and not just write some fancy code that only works in a lab.
Examples: Jenkins, GitLab CI, Azure Pipeline, TeamCity

A Jenkins pipeline - source: Jenkins.io
CD (Continuous Deployment)
What for: Automatically deploy your product
Why: Get product improvements to customers faster
CI and CD are often put together and if you look at the list of example tools, they all do both. But they have different challenges and benefits which is why I separate them out. CI builds and tests our code, CD takes the completed, maybe compiled, output and pushes it towards the user. This could be building an installer that is uploaded to a website for users to download, it could push the latest version of a webserver live or deploy a new machine learning model.
Whilst this step is done at a lower frequency than CI, it still makes sense to automate it. You reduce the risk of making mistakes and mess up that perfect release just because you were too tired to include an important file. But if manual it is slower and there is a bigger gap between that new feature existing in code and being able to give it to your customers. Remember code is just a bunch of text files, until it is built, works (i.e. tested) and in the hands of those that need it, your customers. So making CD easy and slick is really important.
Examples: Jenkins, GitLab CI, Azure Pipeline, TeamCity
Azure Pipeline in action - source: learn.microsoft.com
Environment Management
What for: How to set up a development and product environment.
Why: Fast onboarding, clarify environment requirements
Last but not least you need to be able to define how to create a development setup as well as a product environment. In it’s simplest form you can create a document that describes in detail how to get joining developers, to set up their machine so that they can start coding. What are the tools you need to download and install, what are your environment assumptions? When it comes to python for example, you have environment tools that give you a clean slate to work from and deploy all dependencies.
Same goes for your product environment. What is your target platform you are deploying your product to? How can you recreate this platform? Is it generic or very specific. Once defined again this can be used by both the developers as well as testers to ensure the product performs well.
Examples: Python: poetry, venv, pipenv - General: Docker, text file

Managing Docker images using Docker Desktop - source: Docker.com
Summary
Here a table with all the above condensed down:
| Tool | Example | Process | Benefit |
|---|---|---|---|
| Repository / Hosting | git, subversion, perforce/ GitHub, GitLab, Bitbucket, Azure DevOps | Branching and merging policy, Pull Requests | Build stable code, isolate messy dev work from production |
| Work Tracker | Jira, Azure DevOps, Bugzilla, Trello, (and 100 more) | Plan your work, track features and bugs | Have clear and transparent team priorities. |
| Test Framework / Coverage | Python: PyTest, Coverage C#: MSTest, DotCover, NCover | Create Unit, Integration and End-to-end test, find areas not covered | Ensure product remains stable, support decoupled architecture, code for others |
| Linter / Code Formatting | Python: Pylint, flake8, Pylama / Black, isort, autopep8 C#: ReSharper, EditorCOnfig | Tidy up code while writing, use all the help you can get, enforce coding style | Make code more readable and consistent, so easier to maintain. Write code for others |
| Documentation System | Sphinx, DoxyGen | Create code that documents itself, explain architecture | Make it easy to understand, quick onboarding, design better |
| Code Review System (Pull Requests) | Azure Devops PR, GitHub PR | Get code reviewed before merging to main branch | Improve code quality, share knowledge, team communication |
| CI (Continuous Integration) | Jenkins, GitLab CI, Azure Pipeline, TeamCity | Automatically build and test code changes | Stable software |
| CD (Continuous Deployment) | Jenkins, GitLab CI, Azure Pipeline, TeamCity | Automatically deploy your product | Get product improvements to customers faster |
| Environment Management | Python: poetry, venv, pipenv General: Docker, txt | How to set up a development and product environment. | Fast onboarding, clarify environment requirements |
| IDE | Visual Studio, VS Code, NetBeans, Atom, PyCharm | Your coding environment. | Powerful tools for happy = productive devs |
Conclusion
There you have it - a top to bottom rundown of tools you need to think about when running a team in a production environment. There are many options how to solve each individual workflow, the key thing is to be aware of the benefits each one brings when you embrace it to your own project.
Leave some comments if I have forgotten anything and I will be sure to add it in the future.